Salient points while working with Clustered Index
Assumption –
The reader is expected to have a basic understanding of B-Tree, SQL Server Physical Architecture and Index – Clustered/Non Clustered. If not, then it’s advisable to read it from MSDN.
Why should we always have Clustered Index?
Cluster Index OUT-PERFORMS NonClustered Index since Clustered Index stores the data for every row. Data page is stored in the leaf node of the Clustered Index.
Data is sorted based on clustered index key values and then stored. The only time the data is stored in sorted order when the table contains a clustered index. Sort operation is most costly operator in SQL Server. Since data is stored in sorted order hence sorting on the clustered key column avoids the sort operator and makes it best choice for sorting.
Note: Avoid sorting as much as possible. If it’s really important then do it on the clustered index key column. I have always found sorting (ORDER BY) killing the performance of the query.
Another important use of Clustered Index is – it helps the Database engine to lock a particular row instead of a Page or a Table. Row level locking can be only achieved if table has Clustered Index. SQL Server applies lock on Row, Page or Table to ensure consistency.
Note: Locking, Blocking, Lock Escalation & Deadlocks are beyond the purview of the current write up.
Best practices recommended for Clustered Index column(s).
- It should be as narrow as possible in terms of the number of bytes it stores.
- It should be unique to avoid SQL Server to add Uniquefier to duplicate key values.
- It should be static, ideally, never updated like Identity column.
- It should be ever-increasing, like Identity column to avoid fragmentation and improve the write performance.
Note: Auxiliary factors like Fragmentation; Fill Factor & Page splits etc. are consequential while implementing SQL Server Indexing.
Should we follow the best practices recommended by experts or apply our own use case?
Every Database developer & architect including me frequently face this dilemma, whether to go with the expert recommendations or apply our own use case?
Every solution has implicit tradeoffs. Ratio of advantage vs disadvantage defines whether the solution is optimal or otherwise. In the ever-evolving tech landscape, best practices of today eventually end up being promptly replaced by those of tomorrow.
Let us have a very simple example with one table that holds the Coffee Vending Machine’s Sensor Data. Every second 1000’s of records of multiple machines get written into this table. The scenario here pertains to an application which gets refreshed every 10 seconds and reads past 1 hour of data to render analytics over the UI.
We will apply the best practices and create the Clustered Index on Identity column.
CREATE TABLE Coffee_Vending_Machine_Data ( ID NUMERIC IDENTITY(1,1) NOT NULL , Date_Time DATETIME , MachineID INT , Sensor1_Value INT , Sensor2_Value INT , Sensor3_Value INT , Sensor4_Value INT ) CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data (ID)
Now, it’s time to populate this table with some data to play with it. The query may take some time to execute as we wanted sufficient data for our analysis.
SET NOCOUNT ON DECLARE @RowID INT = 1 , @MachineID INT , @Date_Time DATETIME , @Sensor1_Value INT , @Sensor2_Value INT , @Sensor3_Value INT , @Sensor4_Value INT WHILE (@RowID <= 500000) BEGIN SET @Date_Time = GETDATE(); SET @MachineID = ROUND((RAND() * 10), 0) SET @Sensor1_Value = ROUND((RAND() * 100), 0) SET @Sensor2_Value = ROUND((RAND() * 100), 0) SET @Sensor3_Value = ROUND((RAND() * 100), 0) SET @Sensor4_Value = ROUND((RAND() * 100), 0) INSERT INTO Coffee_Vending_Machine_Data (Date_Time, MachineID, Sensor1_Value, Sensor2_Value, Sensor3_Value, Sensor4_Value) VALUES (@Date_Time, @MachineID, @Sensor1_Value, @Sensor2_Value, @Sensor3_Value, @Sensor4_Value) SET @RowID = @RowID + 1; END
Let’s query the table with our scenario and fetch last one hour of records.
SET STATISTICS IO ON SET STATISTICS TIME ON SET NOCOUNT ON SELECT ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data WHERE Date_Time BETWEEN DATEADD(HOUR, -1, GETDATE()) AND GETDATE()
The STATISTICS augment the above query to see what’s going on behind the scenes. Let’s see the Stats & Execution Plan.


Index scan is avoided at best for any scenario. To avoid the scan either we can create a NonClustered Index on Date_Time column or we can include Date_Time column in the Clustered Index itself. More Indexes in a table foster overhead on the Database Engine and adversely impact the Write performance of the DB.
If we will create another NonClustered Index on Date_Time column then there could be 2 possibilities –
a. NonClustered Index will be Seek and it will involve the Bookmark lookup / Key Lookup ; or
b. There won’t be any NonClustered Index Seek, instead Database engine will decide to do Clustered Index Scan
Let us see the above possibilities in action
Bookmark Lookup
Bookmark Lookup operator occurs if requested column is not a part of the Index being used by the Optimizer. With the help of Bookmark Lookup, the Database Engine retrieves the Column Value for the requested columns from Clustered Index (if Clustered Index is present) or from Data Page based on the Row Identifier (if Clustered Index is absent which implies the table is a Heap).
In case more than one column is requested and they are not part of the Index used by the Optimizer then Database Engine will perform Bookmark Lookup for every Column and eventually combine the result of Index Seek and Bookmark Lookup using a Nested Loops operator. We invariably find Nested Loops in every scenario of Bookmark Lookup as seen in our forthcoming examples.
There are 2 kinds of Bookmark Lookup Operators as follows –
- RID Lookup – RID Lookup occur on a Heap which do not have a Clustered Index.
- Key Lookup – Key Lookup occurs on a table with Clustered Index.
Now, you can relate and imagine the cost of Bookmark Lookup in large datasets.
We will create a NonClustered Index on Date_Time & MachineID column.
CREATE NONCLUSTERED INDEX IX_Coffee_Vending_Machine_Data_Date_Time ON Coffee_Vending_Machine_Data (Date_Time)
Pick any random record from the table. Select Top 10 rows to find one for you.
SELECT TOP 10 ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data
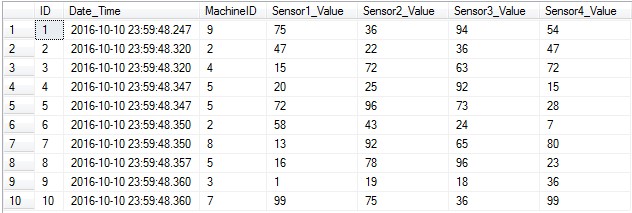
Pick the Date_Time of the first row and rerun the SELECT query with Date_Time as this value.
Input to Date_Time column in the below query will be different in your case because in the example I have used GetDate() function which returned some value at the time of writing this Article and will return different value when you will try it on your own. Choose wisely from the output of the above query.
SELECT TOP 10 ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data WHERE Date_Time = '2016-10-10 23:59:48.247'
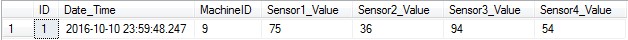

Note – Query returned only 1 row.
We witness NonClustered Index Seek operator working with RID lookup (Bookmark Lookup) operator. We got RID lookup as I have dropped the Clustered Index from the table. RID Lookup operator gets involved only when there is no Clustered Index on the table.
Let’s retain our original Clustered Index on ID column and rerun the same SELECT query with specific Date_Time.
SELECT TOP 10 ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data WHERE Date_Time = '2016-10-10 23:59:48.247'
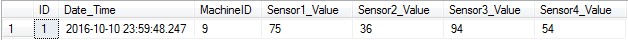
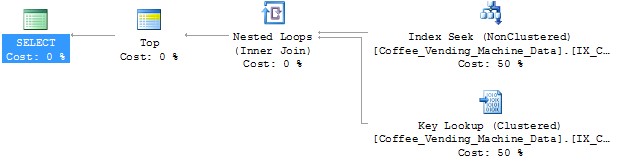
Note – Query returned only 1 row.
We got what we were looking for. It’s a Key Lookup.
Clustered Index Scan
Now, it’s turn to see the Clustered Index Scan in action even when we have NonClustered Index on Date_Time column and Clustered Index present on the table.
SELECT ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data WHERE Date_Time <= '2016-10-11 23:59:48.247'

Note – Query returned 500000 rows.
We find it’s a Clustered Index Scan.
Let’s try to understand why we got the Clustered Index Scan with the similar Index?
Answer is – Optimizer decides to apply the Scan or Seek based on the Cardinality of the Index and Estimated Number of Rows. Statistics play crucial role here as the Optimizer refers the Statistics to get the Estimated Number of Rows to generate the optimal plan. Without Statistics there is no way the Optimizer can get this information. In essence, if Statistics is stale or it’s not updated then we may get the poor plan that may impact the performance of the query adversely.
There are two ways to update the Statistics –
- By setting the Auto Update Statistics Property of Database as True. You can find this property under Option section of Database Property pop window.
- By manually updating it. It’s recommended to update the Statistics as part of the periodic database maintenance activity. You can use sp_updatestats system stored procedure. Refer the documentation for sp_updatestats from MSDN before using it in Production.
Note – If Auto Update Statistics is set as “True” then the Database Engine will automatically update the Statistics. But important point to be noted here is – It’s not instant you INSERT, UPDATE or DELETE the records.
Indexes entail a cost in their usage. MSDN suggests creating any number of NonClustered Index (based on the Maximum Capacity Specification) but it is NEVER advisable to reach the Maximum Capacity Specification. Indexes come with lot of IO overhead and storage overhead to Database engine. A good Index can drastically improve the Database performance and vice-versa.
SQL Server doesn’t allow creation of more than one Clustered Index because Clustered Index also holds the actual Data Page in its leaf level node. It implies the table is going to consume the double the size of data.
Whereas, we can create multiple NonClustered Index on a table. But freedom has some inevitable tradeoffs which we have already discussed. Having multiple indexes cause inevitable IO overhead and impacts the write operation performance, adversely, which could in turn cause locks and after the reaching the Threshold; eventually SQL DB engine will initiate the lock escalation and it may result in Page or Table lock which in turn can become contributor to further Deadlocks.
Note: Discretion mandates thinking twice before adding any new Index to table.
Decision to scan or seek a particular Index is taken by the Optimizer based on the Statistics available for the Index. If optimizer thinks that scanning the whole rows will be the optimized way than doing seek then it will opt for scan. Scan could be Clustered Index Scan, NonClustered Index Scan or Table Scan. That is why it is highly recommended to filter the tables used in the query as much as possible. A strong filter predicate is CERTAINLY more helpful in optimizing the query. All the Joins should happen strictly on the filtered dataset.
Now, instead of creating NonClustered Index, let’s change our Clustered Index and make it composite with Date_Time & ID columns.
Note: Choosing the sequence of Column also matters in Index selection. Indexes with better cardinality performs better and vice-versa.
Step 1 – Drop the existing Clustered Index
DROP INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data
Step 2 – Create new Clustered Index on Date_Time & ID columns
CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_Date_Time_ID ON Coffee_Vending_Machine_Data (Date_Time, ID)
We have now changed the Clustered Index, let’s see the difference by executing the original SELECT query.
SET STATISTICS IO ON SET STATISTICS TIME ON SET NOCOUNT ON SELECT ID , Date_Time , MachineID , Sensor1_Value , Sensor2_Value , Sensor3_Value , Sensor4_Value FROM Coffee_Vending_Machine_Data WHERE Date_Time BETWEEN DATEADD(HOUR, -1, GETDATE()) AND GETDATE()


If you have noticed then there is not much of a difference in the Stats of both the examples but there is change in the Execution Plan. Now the Clustered Index is getting Seek instead of Scan in earlier example. Clustered Index Seek is always better to have in the Execution Plan. It helps to prevent the Scan & lookup cost. The example we have discussed is very basic – just imagine if this table is getting 1000’s of records per second then it means that this table will be growing by 86400000 rows every day. Every minor decision could have a major impact. Here we wanted to strike a balance in performance of both Writes & Reads. Index decision specially Clustered Index plays vital role in the Database performance.
It is also true that only Indexes will not be sufficient to live with high data volume as discussed above. Data Archival strategy is an absolute must to deal with enormous data volumes. We also cannot perform the Data Archival very frequently so what to do in such a situation? We shall be looking into the nuances of it in a follow up Article.
Conclusion –
There could be numerous approach for dealing with the scenario mentioned in the article (including choosing the indexes, columns for the indexes and sequence of columns in the indexes). We have just taken a simple example to understand the working of Clustered Index.
There is no PANACEA solution so it’s always advisable to evaluate every recommendation and its trade-offs holistically before actually applying it. There could be two methods to deal with the problems – proactive and reactive. It’s always good to be proactive than reactive.
Motivation and moral support behind this Article –
I would like to thank to Vinod Naidu, Saikiran Gangam and Saumitra Bhardwaj for all the motivation and support they gave me to take this initiative.
Thanks a plenty for reading and I fervently hope it’s been worth your while.
References –
- https://www.simple-talk.com/sql/learn-sql-server/effective-clustered-indexes/
- https://msdn.microsoft.com/en-us/library/mt590198(v=sql.1).aspx
Disclaimer –
This is a personal weblog. The opinions expressed here represent my own and not those of my employer.
All data and information provided on this site by Author is for informational purposes only. Author makes no representations as to accuracy, completeness, correctness, suitability, or validity of any information on this site and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use.
Please don’t use any of the examples discussed in this article in Production without evaluating it based on your need.

One thought on “Working with Clustered Index – SQL Server”