First published on: 2020-03-14
Introduction
Official Microsoft documentation on Columnstore indexes says
This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage. You can also achieve gains up to 10 times the data compression over the uncompressed data size. Beginning with SQL Server 2016 (13.x), columnstore indexes enable operational analytics: the ability to run performant real-time analytics on a transactional workload.
In this article, our focus will be to test, the performance benefits of columnstore indexes, on a transactional (OLTP) workload, for real-time analytics.
Scope of test
We’ll cover examples from each of the followings – Pivot, Aggregate Functions, Analytic Functions, Ranking Functions and Window Functions.
Prerequisites
We need to have a table loaded with lot of data. We also need set of queries, that we’ll refer to test the performance.
Sample Data
After executing the below query, we’ll have 14,74,600 rows. That’ll be sufficient for our test.
CREATE TABLE tbl_Account_Balance ( ID NUMERIC NOT NULL IDENTITY(1, 1) , CustomerID INT , Transaction_Date DATE , Credit NUMERIC(18, 2) , Debit NUMERIC(18, 2) ) GO DECLARE @Date DATE SET @Date = '2000-01-01' WHILE @Date <= '2020-03-08' BEGIN INSERT INTO tbl_Account_Balance ( CustomerID , Transaction_Date , Credit , Debit ) VALUES ( FLOOR(RAND() * 100) , @Date , (RAND() * 100000) , 0 ) INSERT INTO tbl_Account_Balance ( CustomerID , Transaction_Date , Credit , Debit ) VALUES ( FLOOR(RAND() * 100) , @Date , 0 , (RAND() * 100000) * -1 ) SET @Date = DATEADD(DAY, 1, @Date) END GO 100
Sample Queries
These queries will be used repeatedly all along. We’ve three queries, each for :
- Pivot – We’ll give it a name “Query_Pivot”
- Aggregate Function – We’ll give it a name “Query_Aggregate”
- Analytic, Ranking & Windowing Functions – We’ll give it a name “Query_Analytic”
We’ll further use these names to refer to the queries.
-- ################################### Pivot ################################### DECLARE @START_DATETIME DATETIME , @END_DATETIME DATETIME SET @START_DATETIME = GETDATE() SELECT [CustomerID] , [2000], [2001], [2002], [2003], [2004], [2005], [2006] , [2007], [2008], [2009], [2010], [2011], [2012], [2013] , [2014], [2015], [2016], [2017], [2018], [2019], [2020] FROM ( SELECT CustomerID , YEAR(Transaction_Date) AS Trxn_Year , (Credit - Debit) AS Balance FROM tbl_Account_Balance (NOLOCK) ) RD PIVOT ( SUM(Balance) FOR Trxn_Year IN ([2000], [2001], [2002], [2003], [2004], [2005], [2006] , [2007], [2008], [2009], [2010], [2011], [2012], [2013] , [2014], [2015], [2016], [2017], [2018], [2019], [2020]) ) PV SET @END_DATETIME = GETDATE() SELECT DATEDIFF(MILLISECOND, @START_DATETIME, @END_DATETIME) AS ExecutionTime_MS --################################### Aggregate Functions ################################### DECLARE @START_DATETIME DATETIME , @END_DATETIME DATETIME SET @START_DATETIME = GETDATE() SELECT CustomerID , YEAR(Transaction_Date) AS Trxn_Year , SUM(Credit - Debit) AS Balance_Sum , AVG(Credit - Debit) AS Balance_Avg , MIN(Credit - Debit) AS Balance_Min , MAX(Credit - Debit) AS Balance_Max , COUNT(CustomerID) AS CustomerID_Count FROM tbl_Account_Balance GROUP BY CustomerID , YEAR(Transaction_Date) SET @END_DATETIME = GETDATE() SELECT DATEDIFF(MILLISECOND, @START_DATETIME, @END_DATETIME) AS ExecutionTime_MS --################################### Analytic, Ranking & Windowing Functions ################################### DECLARE @START_DATETIME DATETIME , @END_DATETIME DATETIME SET @START_DATETIME = GETDATE() SELECT CustomerID , Transaction_Date , Credit , Debit , FIRST_VALUE(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_FV , LAST_VALUE(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_LV , LEAD(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_NV , LAG(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_PV , SUM(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_Sum , AVG(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_Avg , MIN(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_Min , MAX(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_Max , COUNT(Credit) OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS Credit_Count , ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS RowNumber , DENSE_RANK() OVER(PARTITION BY CustomerID ORDER BY Transaction_Date ASC) AS DenseRank FROM tbl_Account_Balance SET @END_DATETIME = GETDATE() SELECT DATEDIFF(MILLISECOND, @START_DATETIME, @END_DATETIME) AS ExecutionTime_MS<span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span>
Benchmark
Since we are going to test the performance, hence we need to have some benchmark. Here we’ll have two benchmarks. First benchmark will be the execution time with rowstore index, and second benchmark will be the execution time without any index.
We’ll perform 5 rounds of executions of Sample Queries as follows:
- 1 execution with Clustered Index (Rowstore), and ;
- 1 execution with Clustered Columnstore Index, and;
- 2 executions with NonClustered Columnstore Index, and ;
- finally 1 execution without any index.
Important Notes
Server Configuration
This test has been performed on the server with following configurations.
- OS : Windows Server 2019 Datacenter 10.0 <X64> (Build 17763: ) (Hypervisor)
- SQL Server : SQL Server 2019 Developer Edition (64-bit)
- RAM : 4 GB
- Cores : 2 Virtual Cores
- Disk Performance (Estimated)
- IOPS limit : 500
- Throughput limit (MB/s) : 60
- On-Premises/Cloud : Azure Cloud
Rowstore Index
Since we don’t have any filtration (where clause) in our queries, hence we’ll consider Clustered Index.
Execution of the queries
I’ve executed the queries multiple times (Approx. 5+ times) to arrive at the execution time and plan. Each time, queries were executed with Include Actual Execution Plan option.
Round 1 – Execution with Clustered Index (Rowstore)
Script to create the clustered index.
CREATE CLUSTERED INDEX CIX_tbl_Account_Balance_Credit_Debit ON tbl_Account_Balance (ID)
Execution of Query_Pivot


Execution of Query_Aggregate


Execution of Query_Analytic
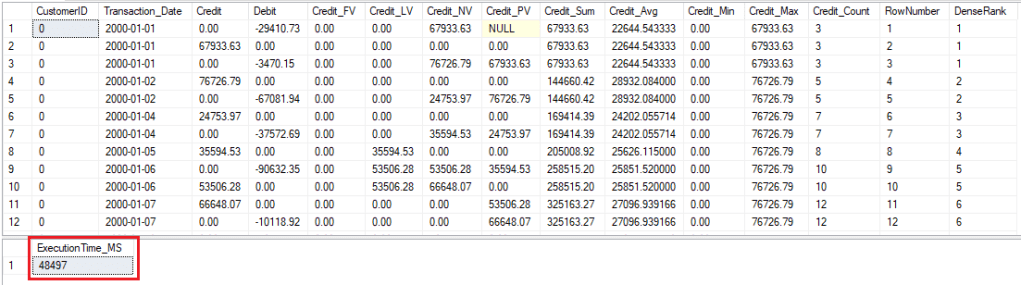

Round 2 – Execution with Clustered Columnstore Index
Script to drop existing clustered index and create the clustered columnstore index.
DROP INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance
GO
CREATE CLUSTERED COLUMNSTORE INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance
Execution of Query_Pivot
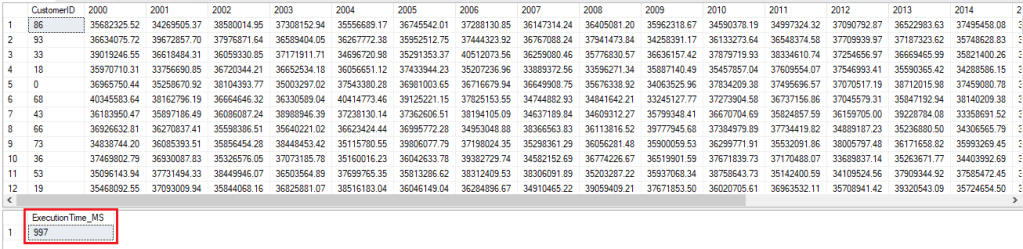

Execution of Query_Aggregate


Execution of Query_Analytic


Round 3 – Execution with NonClustered Columnstore Index on 4 columns
Script to drop existing clustered index and create the nonclustered columnstore index on all the columns (excepting ID column).
DROP INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance (CustomerID, Transaction_Date, Credit, Debit)
Execution of Query_Pivot
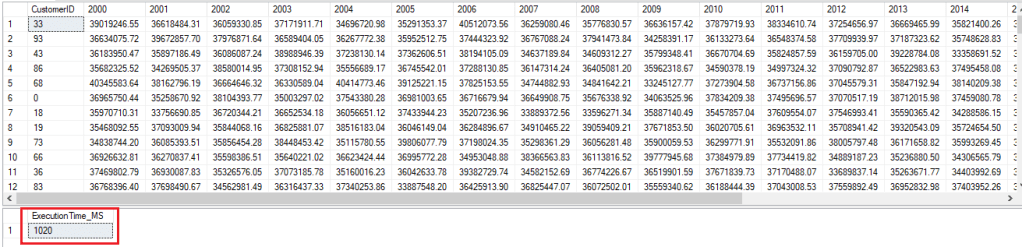

Execution of Query_Aggregate
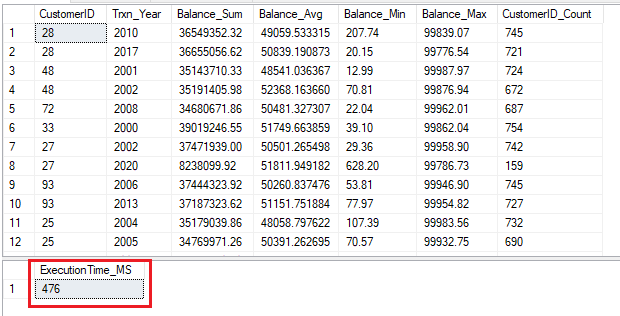

Execution of Query_Analytic
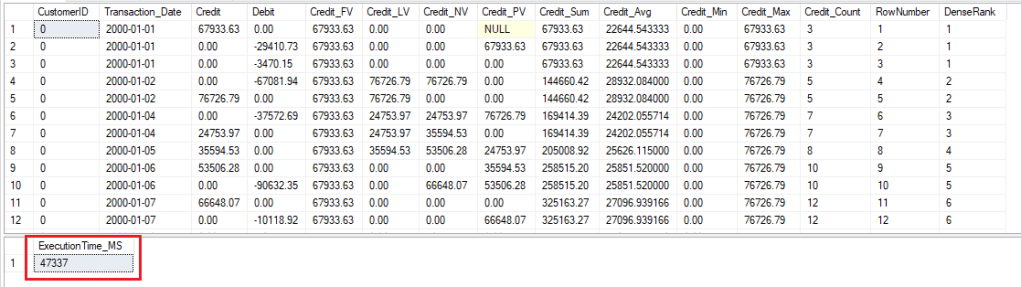

Round 4 – Execution with NonClustered Columnstore Index on 2 columns
Script to drop existing clustered index and create the nonclustered columnstore index only on Credit & Debit columns.
DROP INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance (Credit, Debit)
Execution of Query_Pivot
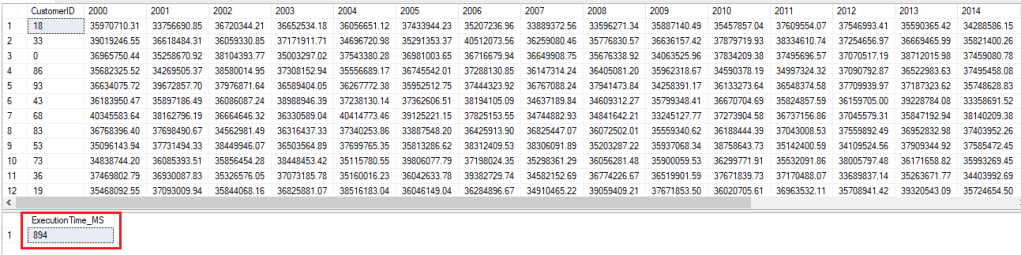

Execution of Query_Aggregate
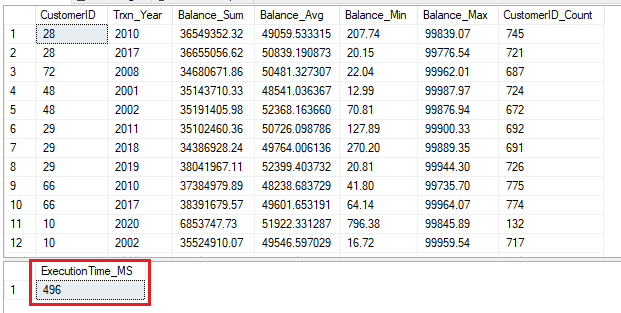

Execution of Query_Analytic
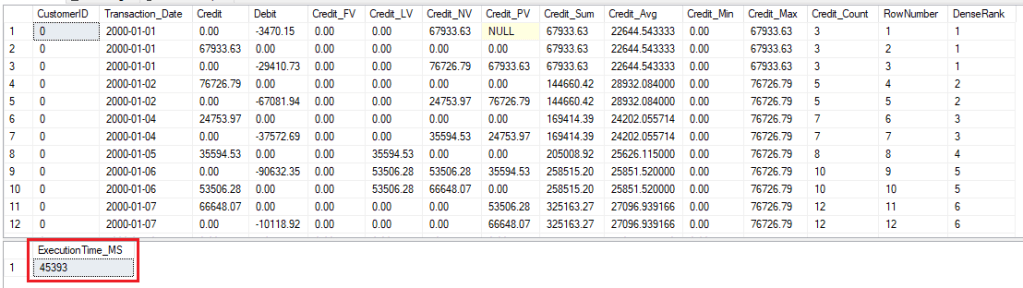

Round 5 – Execution without any Index
Script to drop existing clustered index.
DROP INDEX CIX_tbl_Account_Balance
ON tbl_Account_Balance
Execution of Query_Pivot

Execution of Query_Aggregate

Execution of Query_Analytic

Findings – Performance Comparison

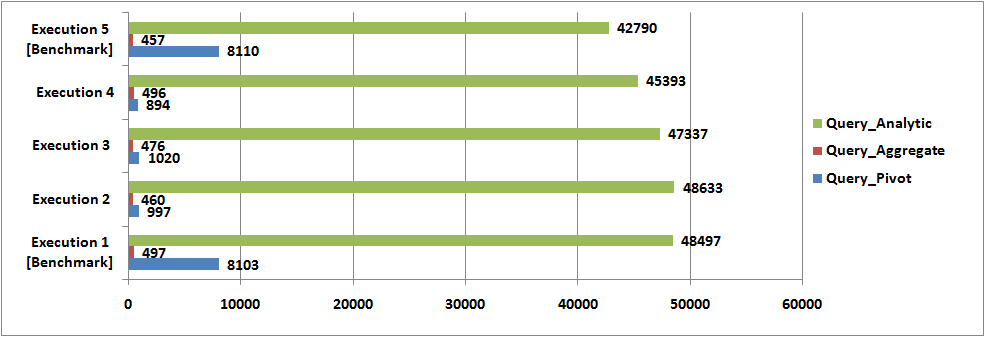
Pivot
We’ve observed performance gains upto 10 times, with Columnstore Index.
Clustered Columnstore Index didn’t played well for us.
NonClustered Columnstore Index on 2 columns i.e. Credit & Debit, that participated in the arrival of Balance, and finally in the Pivot, outperformed NonClustered Columnstore Index on 4 columns (CustmerID, Transaction_Date, Credit and Debit).
However, the conclusion could be NonClustered Columnstore Index outperformed Clustered Index (Rowstore), which was our benchmark.
Aggregate Functions
There has been no considerable performance gains. Execution time was almost same for all 5 rounds of executions.
Analytic, Ranking and Window Functions
There has been no considerable performance gains. Although, execution without any index was slightly better.
Conclusion
Columnstore Indexes were introduced in SQL Server 2012. Microsoft is doing continuous enhancements in this feature. But this feature is not being explored much for OLTP, at-least basis what I’ve seen. It’s being considered more suitable for DW and Analytic workload.
Pivot is one of the costliest operation in SQL Server. I’ve to personally re-model one of the production database in SQL Server 2008 R2, belonging to IIoT workload.
Reason was simple – Multiple Pivots were used, and were getting triggered quite frequently. Our read load was killing the resources, even after increasing the capacity. We struggled for months, but no luck.
Thanks to Microsoft and SQL Server team for bringing-in this feature.
Columnstore Indexes out-performs in some cases (like we saw for Pivot) as compared to Rowstore Indexes because :
- It allows better compression. Data to be physically stored column wise as compared to its ancestor Rowstore Indexes, that stores data row wise.
- Since data is highly compressed, more data can be accommodated in memory. More data in memory means less Disk IO and associated CPU utilization.
In my limited opinion, columnstore indexes should not be considered the one stop solution, for all the index requirements. It should be used wisely in OLTP for specific workloads, such as Aggregation, Pivot etc. It shouldn’t be used as an alternative, to rowstore indexes, for avoiding lookup cost.
Further Reading
Readers are highly advised, to read the following Microsoft official documentation, before implementing the Columnstore Indexes, in a production workload.
Get started with Columnstore for real-time operational analytics

Hello,
Thanks for sharing wonderful comparison in this post.
But if I would apply nonclustored index on table and then if I will find performance, it may outperform than clustored columnstore index.
Please let me know your thoughts too.
LikeLike
Thanks Dhruv!
It depends on the workload. If the requirement is to avoid lookup cost (Index seek, Key lookup, RID lookup etc.) then rowstore index (Clustered/Nonclustered) could be the best candidate.
As we seen in our test, query without any index performed better than any other executions with variety of indexes. So it totally depends on the workload and scenario.
One more important point to note is SQL Server Optimizer plays important role to decide which approach will be better. For e.g. if a table has 10 rows and it has clustered or non clustered index, so optimizer decides that table scan will be faster than Index seek so it does the table scan.
Columnstore index helps in case of analytics workload. It helps achieve high level of compression due to which more data can be accommodated in the memory, which means less Disk IO and associated CPU overhead. But this also has trade-off. Compression itself is overhead that will impact the write performance.
Both Columnstore and Rowstore has its own specific importance and keeping right balance between them is an art of DBA/Database Architect.
I hope you will find my response satisfactory!
LikeLike
Thank you for the detailed post, especially the code. I’m brand new to columnstore but I’m looking at the possibility of columnstore indexes on a billion row audit table. The more I thought about it, the less I liked the idea and was looking for some confirmation about my discomfort on it all. This article says I was right in my discomfort. You’ve saved me a good bit of time and testing. Thank you.
LikeLike