Introduction
Computed Columns can be utilized to optimize the query performance. It can be leveraged, to make the query sargeable, to make proper use of available indexes.
In this article, we’ll perform a test to see, how computed columns can help in performance tuning.
Scenario for our test
I’ve taken an example of invoice table with attributes such as Invoice No, Customer ID, Order Qty and Order Rate.
Invoice Number is a varchar(12) column which is the combination of :
First 2 characters are Product Code
Next 6 characters are Order Number
Last 4 characters are Year of purchase
We are expected to write a stored procedure to accept Order No as Input and returns the Invoice details.
Table & Data script
CREATE TABLE Invoice_Details
(
Invoice_Number VARCHAR(12)
, Customer_ID INT
, Order_Qty DECIMAL
, Order_Rate DECIMAL
)
; WITH cte_invoice
AS
(
SELECT 100000 AS Start_Number
, CHAR((65 + FLOOR(RAND() * 10))) + CHAR((65 + FLOOR(RAND() * 10))) + CAST(100000 AS VARCHAR) + CAST(YEAR(GETDATE()) AS VARCHAR) Invoice_Number
, FLOOR((RAND() * 100000)) AS Customer_ID
, (RAND() * 10) AS Order_Qty
, (RAND() * 100) AS Order_Rate
UNION ALL
SELECT (Start_Number + 1) AS Start_Number
, CHAR((65 + FLOOR(RAND() * 10))) + CHAR((65 + FLOOR(RAND() * 10))) + CAST((Start_Number + 1) AS VARCHAR) + CAST(YEAR(GETDATE()) AS VARCHAR) Invoice_Number
, FLOOR((RAND() * 100000)) AS Customer_ID
, (RAND() * 10) AS Order_Qty
, (RAND() * 100) AS Order_Rate
FROM cte_invoice
WHERE Start_Number < 999999
)
INSERT INTO Invoice_Details
(
Invoice_Number
, Customer_ID
, Order_Qty
, Order_Rate
)
SELECT Invoice_Number
, Customer_ID
, Order_Qty
, Order_Rate
FROM cte_invoice
OPTION (MAXRECURSION 0);
Let’s start the test
First approach (without using Computed Column)
CREATE PROCEDURE usp_Get_Invoice_Details_By_Order_Number
(
@Order_Number INT
)
AS
BEGIN
SET NOCOUNT ON;
SELECT Invoice_Number
, Customer_ID
, Order_Qty
, Order_Rate
FROM Invoice_Details
WHERE SUBSTRING(Invoice_Number, 3, 6) = @Order_Number
END
Let’s execute the stored procedure to check the execution time, plan and stats
DECLARE @Start_Time DATETIME
, @End_Time DATETIME
SET @Start_Time = GETDATE()
SET STATISTICS IO ON
EXEC usp_Get_Invoice_Details_By_Order_Number @Order_Number = 999999
SET STATISTICS IO OFF
SET @End_Time = GETDATE()
SELECT DATEDIFF(MILLISECOND, @Start_Time, @End_Time)
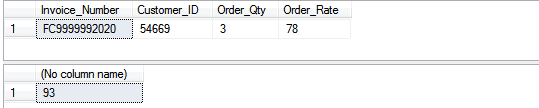
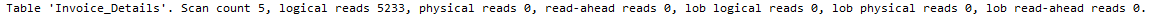

Oops! Table scan and too many logical reads.
Let’s try an Index
I choose to create the Covering Index to avoid Bookmark Lookup
CREATE NONCLUSTERED INDEX IX_Invoice_Details ON Invoice_Details (Invoice_Number)
INCLUDE (Customer_ID, Order_Qty, Order_Rate)
Now, let’s execute the stored procedure again and review execution time, plan and stats.

Disappointing result! No change in execution time, stats and execution plan. Hence, let’s try another approach with computed column.
Second approach (using Computed Column)
We’ll drop the existing index, create a computed column and create a new covering index on computed column.
ALTER TABLE Invoice_Details
ADD Order_Number AS CAST(SUBSTRING(Invoice_Number, 3, 6) AS INT) PERSISTED
GO
DROP INDEX IX_Invoice_Details ON Invoice_Details
GO
CREATE NONCLUSTERED INDEX IX_Invoice_Details ON Invoice_Details (Order_Number)
INCLUDE (Invoice_Number, Customer_ID, Order_Qty, Order_Rate)
Now, we’ll modify our stored procedure to use the computed column.
ALTER PROCEDURE usp_Get_Invoice_Details_By_Order_Number
(
@Order_Number INT
)
AS
BEGIN
SET NOCOUNT ON;
SELECT Invoice_Number
, Customer_ID
, Order_Qty
, Order_Rate
FROM Invoice_Details
WHERE Order_Number = @Order_Number
END
Now, let’s execute the modified stored procedure and review execution time, plan and stats.
DECLARE @Start_Time DATETIME
, @End_Time DATETIME
SET @Start_Time = GETDATE()
SET STATISTICS IO ON
EXEC usp_Get_Invoice_Details_By_Order_Number @Order_Number = 999999
SET STATISTICS IO OFF
SET @End_Time = GETDATE()
SELECT DATEDIFF(MILLISECOND, @Start_Time, @End_Time)

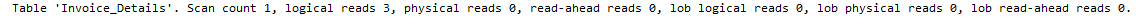

Execution Time : < 1 MS as compared to earlier 90 MS. Bravo! Performance improvement up-to 90x times.
IO Stats : Logical reads reduced to 3 from earlier 5233
Execution Plan : Index Seek instead of earlier Table Scan.
Other consideration
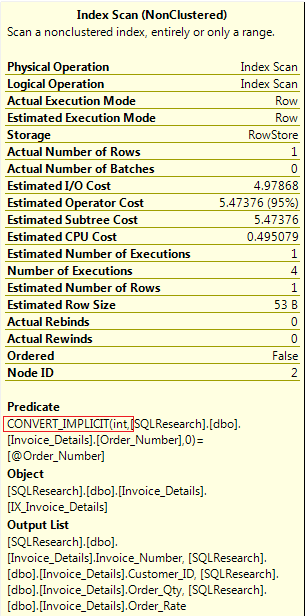
If we’ll not convert the computed column formula to INT, then there will be implicit conversion, and we won’t experience any performance improvement.
If you’ll notice the datatype of input parameter then it’s INT. So either we should change the datatype of input parameter, or apply the conversion in the formula of computed column.
Here is the execution time, stats and execution plan with implicit conversion.

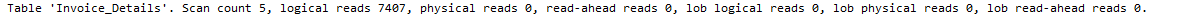

Conclusion
Computed Column can be used to make the queries sargeable. Sargeable query performs better by utilizing the available indexes.
We’ve also noticed, computed column alone won’t make a difference. Hence, there is a need of – search predicates to be of proper datatype, and/or the computed column should be of the proper data type, to avoid implicit conversion.
